1、Spark概述 1、什么是Spark 定义 Spark是一种基于内存的快速、通用、可扩展的大数据分析引擎。 历史 2009年诞生于加州大学伯克利分校AMPLab,项目采用Scala编写。 2010年开源; 2013年6月成为Apache孵化项目 2014...
”Spark! spark wordcount java“ 的搜索结果
MapReduce是Hadoop生态中的一个分布式计算框架。通过使用它,开发人员不必关心分布式计算底层怎么去实现,只需关心相应的业务逻辑,就可以轻松地编写应用程序,以可靠、容错的方式并行处理大型硬件集群上的大量数据...
spark命令提交接口
非结构化数据(Unstructured Data) :非结构化数据是相对于结构化数据而言的,有全文文本、图像、声音、影视、超媒体等形式,并以文件存储,这些数据形式就属于非结构化数据。结构化数据(Structured Data) :结构化数据是...
这种错误往往让人摸不着头闹,...java.lang.IllegalStateException: User did not initialize spark context! at org.apache.spark.deploy.yarn.ApplicationMaster.runDriver(ApplicationMaster.scala:512) at ...
1.hadoop定义Hadoop是一个开源的大数据处理框架,由Java语言编写,专门用于解决海量数据的存储和计算问题2.hadoop的优缺点优点高可靠:具有按位存储和处理数据能力的高可靠性高扩展:通过可用的计算机集群分配数据,...
spark通达OA插件,加载后增加OA卡片,点击显示oa登录界面,将通达oa整合到spark中
hadoop是什么 mapreduce概述 spark概述
StreamAnalytix Visual Spark Studio !Spark开发史上最强大的神器,只需拖拽控件即可完成Spark开发,造福国内的Spark开发者!分钟级别在桌面上构建Spark管道!StreamAnalytix Visual Spark Studio是什么? Visual ...
StreamAnalytix Visual Spark Studio (二)!Spark开发史上最强大的神器,只需拖拽控件即可完成Spark开发,造福国内的Spark开发者!StreamAnalytix Visual Spark Studio (一)简介:...
部署Spark集群大体上分为两种模式:单机模式与集群模式大多数分布式框架都支持单机模式,方便开发者调试框架的运行环境。
目录一、Spark概述(1)概述(2)Spark整体架构(3)Spark特性(4)Spark与MR(5)Spark Streaming与Storm(6)Spark SQL与Hive二、Spark基本原理(1)Spark Core(2)Spark SQL(3)Spark Streaming(4)Spark基本...
YARN(Spark on YARN模式)是一款资源调度管理系统,支持动态资源分配策略,可以为Spark提供资源调度服务,由于在生产环境中,很多时候都要与Hadoop同在一个集群,所以采用YARN来管理资源调度,可以降低运维成本和...
按回车键提交Spark作业后,观察Spark集群管理界面,其中“Running Applications”列表表示当前Spark集群正在计算的作业,执行几秒后,刷新界面,在Completed Applications表单下,可以看到当前应用执行完毕,返回...

1、在存储方式上,HDFS以文件为单位,每个文件大小为 64M~128M, 而mongo则表现的更加细颗粒化; 2、MongoDB支持HDFS没有的索引概念,所以在读取速度上更快; 3、MongoDB更加容易进行修改数据; ...
Spark在2013年加入Apache孵化器项目,之后获得迅猛的发展,并于2014年正式成为Apache软件基金会的顶级项目。Spark生态系统已经发展成为一个可应用于大规模数据处理的统一分析引擎,它是基于内存计算的大数据并行计算...

Spark系列之Spark启动与基础使用
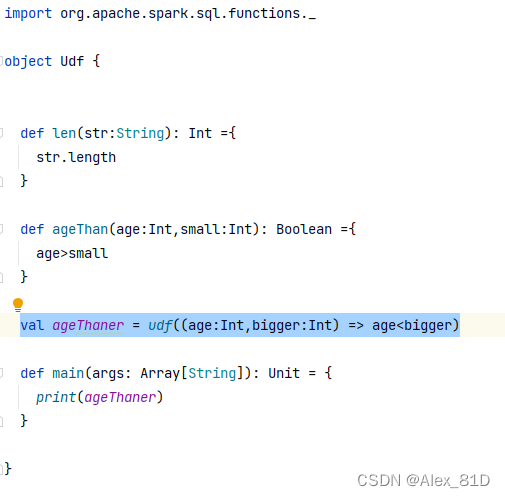

在IDEA中运行spark程序
然后,我们将通过实际的运行架构实例分析,来具体了解Spark在不同的集群模式下的运行架构和工作流程。Spark应用在集群.上运行时,包括了多个独立的进程,这些进程之间通过驱动程序(Driver Program)中的SparkContext...
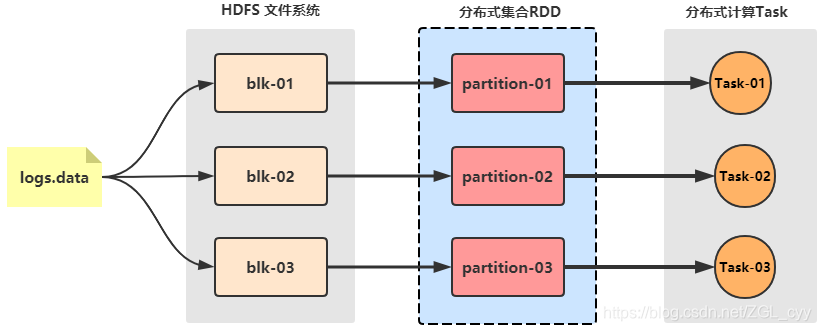
park为了解决以往分布式计算框架存在的一些问题(重复计算、资源共享、系统组合),提出了一个分布式数据集的抽象数据模型:RDD(Resilient Distributed Datasets)弹性分布式数据集。


花了将近一个月时间学习了Spark,为了总结所学知识,我用ProcessOn绘制了几张Spark思维导图 这里是Spark思维导图地址 Spark思维导图地址 注意:需要有ProcessOn账号才能查看 1.Spark 入门 2.Spark Core 3.Spark ...
推荐文章
- 大数据和云计算哪个更简单,易学,前景比较好?_大数据和云计算哪个好-程序员宅基地
- python操作剪贴板错误提示:pywintypes.error: (1418, 'GetClipboardData',线程没有打开的剪贴板)...-程序员宅基地
- IOS知识点大集合_ios /xmlib.framework/headers/xmmanager.h:66:32: ex-程序员宅基地
- Android Studio —— 界面切换_android studio 左右滑动切换页面-程序员宅基地
- 数据结构(3):java使用数组模拟堆栈-程序员宅基地
- Understand_6.5.1175::New Project Wizard_understand 6.5.1176-程序员宅基地
- 从零开始带你成为MySQL实战优化高手学习笔记(二) Innodb中Buffer Pool的相关知识_mysql_global_status_innodb_buffer_pool_reads-程序员宅基地
- 美化上传文件框(上传图片框)_文件上传框很丑-程序员宅基地
- js简单表格操作_"var str = '<table border=\"5px\"><tr><td>序号</td><-程序员宅基地
- Power BI销售数据分析_powerbi汇总销售人员业绩包括无销售记录的人-程序员宅基地